Bevezető
Egy biztosítótársaság pénzügyi működésének és értékesítési hálózatának alapköve a jutalékelszámolás. Ha a jutalékszámítási rendszerben hiba lép fel, az nemcsak közvetlen anyagi veszteséget jelent, hanem azonnal erodálja az értékesítési ügynökök bizalmát is.
Egy ilyen komplex rendszer teszteléséhez óriási mennyiségű, változatos és élethű életúttal rendelkező adatra van szükség. Ugyanakkor a szigorú adatvédelmi szabályozások (GDPR) miatt az éles ügyfél- és partneradatok felhasználása szigorúan tilos. Erre a kihívásra válaszul a biztosító egy generatív mesterséges intelligenciára (CTGAN és TVAE modellekre) épülő szintetikus tesztadat-generátort fejlesztett ki.
Ebben az esettanulmányban bemutatjuk, hogyan tervezte meg és hajtotta végre a minőségbiztosítási csapat a mesterséges intelligencia-alapú adatgenerátor átfogó tesztelését, garantálva, hogy az AI által gyártott adatok statisztikailag pontosak, üzletileg konzisztensek és garantáltan GDPR-kompatibilisek legyenek, mielőtt ráengedték volna őket a kritikus jutalékelszámoló rendszerre.
Szerzői megjegyzés: Ezt az esettanulmányt a projekt megvalósításában részt vevő minőségbiztosítási csapat, az AI/ML tesztmérnökök és az adatmérnökök beszámolói, valamint a belső projekt-dokumentációk alapján állítottam össze. Jómagam közvetlenül nem vettem részt a projekt végrehajtásában; az írás célja a szakmai tapasztalatok és minőségbiztosítási tanulságok szintetizálása volt.
Háttér
A projekt hátterében egy nagy biztosítótársaság jutalékelszámolási rendszerének migrációja és modernizációja állt. A jutalékszámítás rendkívül bonyolult üzleti szabályokat követ: a kifizetés mértéke függ a termék típusától, a közvetítő (ügynök) szintjétől (junior, medior, senior, partner), a kötés időpontjától, az egyedi kedvezményektől, valamint olyan időbeli eseményektől, mint a havi díjfizetések vagy a szerződésbontás miatti jutalék-visszaírások (storno).
A korábbi tesztelési megközelítések megbuktak:
- A manuálisan, Excelben összerakott néhány tucat teszteset nem fedte le a valós élethelyzetek statisztikai eloszlását és a milliókból álló kombinációs lehetőségeket.
- A korábbi, éles adatok maszkolásán (pl. nevek cseréje) alapuló módszer nem nyújtott elégséges adatvédelmi garanciát a szigorú belső compliance és a GDPR auditok előtt.
A generatív AI (Synthetic Data Vault – SDV) bevezetése ígéretes megoldásnak tűnt. Azonban a minőségbiztosítási csapatnak választ kellett adnia a legfontosabb kérdésre: Hogyan bizonyosodhatunk meg arról, hogy az AI által generált adatok nem tartalmaznak rejtett hibákat, nem sértik meg az adatbázis relációs szabályait, és nem szivárogtatnak ki valós személyes adatokat?
A tesztelési csapat felépítése
Egy mesterséges intelligenciát tartalmazó alkalmazás tesztelése keresztfunkcionális megközelítést igényel. A QA csapatot kifejezetten erre a célra hoztuk létre, a következő szerepkörökkel:
- Tesztvezető – a tesztelési stratégia kidolgozásáért, az audit-megfelelőségért és a határidők tartásáért felelt.
- AI/ML QA Mérnök (2 fő) – a generatív modellek működésének tesztelésére, a statisztikai vizsgálatok elvégzésére és a modell-metrikák követésére szakosodott tesztelők.
- Adatmérnök (Data Engineer) – a sémák leképezéséért, a tesztadatbázisok előkészítéséért és a relációs integritás ellenőrzéséért felelt.
- Üzleti Tesztelők és Aktuáriusok (2 fő) – az üzleti szabályok és a jutalékelméleti edge case-ek manuális validálását végezték.
- Automata tesztelő – a tesztadat-generáló script MLOps pipeline-ba (Jenkins) történő integrálásáért és az automatizált ellenőrző futásokért felelt.
- Adatvédelmi és GDPR szakértő – az adatvédelmi penetrációs tesztek tervezéséért és a jogi megfelelőség igazolásáért felelt.
A kihívás: nem-determinisztikus működés és a “Test Oracle” probléma
Az AI-alapú rendszerek tesztelése alapvető módszertani kihívás elé állította a csapatot:
- A Test Oracle hiánya: A hagyományos szoftverteszteknél minden bemenethez tartozik egy előre meghatározott, egzakt elvárt eredmény (pl. 2+2=4). Egy generatív AI modellnél (mint a CTGAN) nincs egyetlen helyes kimenet – a generált adathalmaz minden futásnál más és más lesz, miközben a globális statisztikai tulajdonságoknak azonosnak kell maradniuk.
- Relációs integritás megőrzése (Foreign Key Integrity): Az adatok nem izolált táblákban állnak. Egy ügynökhöz több szerződés, azokhoz több tranzakció kapcsolódik. Ha az AI külön-külön generálja a táblákat, a kulcs-összefüggések megsérülnek, és a tesztrendszer azonnal visszautasítja az adatokat.
- Időbeli konzisztencia: A biztosítási életutak logikai sorrendjét az AI-nak szigorúan követnie kell (pl. nem létezhet jutalék-visszaírás olyan szerződésre, amelyet még meg sem kötöttek).
- Overfitting és adatszivárgás: Fennállt a veszélye, hogy a modell “túl tanulja” a történelmi adatokat, és a szintetikus adatok közé véletlenül belekeveri a valós ügyfelek érzékeny adatait (pl. pontos név és adóazonosító jel együttes előfordulása).
A stratégia: Négy szintű AI-tesztelési keretrendszer
A kihívások leküzdésére a QA csapat egy négy szintből álló, strukturált tesztelési keretrendszert dolgozott ki és valósított meg.
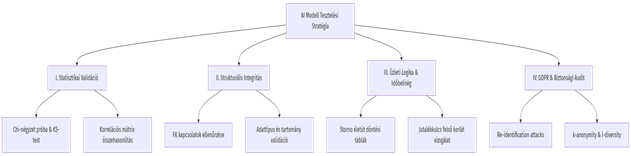
I. Statisztikai és eloszlásvizsgálat (Fidelity & Diversity)
A cél annak ellenőrzése volt, hogy az AI által generált adatok hűen tükrözik-e a valóság mintázatait, torzítások nélkül.
- Kolmogorov-Smirnov (KS) teszt: A folytonos változók (pl. biztosítási összegek, kifizetett jutalékok) eloszlásának összehasonlítására. A tesztelők elvárták, hogy az AI-generált adatok legalább 95%-os valószínűséggel kövessék az éles adatok eloszlását.
- Chi-négyzet (
 ) függetlenségvizsgálat: A kategóriás változók (pl. ügynök szintje, terméktípusok aránya) eloszlásának ellenőrzésére.
) függetlenségvizsgálat: A kategóriás változók (pl. ügynök szintje, terméktípusok aránya) eloszlásának ellenőrzésére. - Korreláció-megőrzési teszt (Pearsons-féle R): A változók közötti kapcsolatok ellenőrzése. Például az AI-nak meg kellett tartania azt a szabályt, hogy a magasabb ügynöki szinthez magasabb átlagos jutalékkulcs társul.
II. Strukturális és relációs integritás tesztelése
Az adatbázis-séma megfelelőségének ellenőrzése.
- Idegen kulcsok konzisztenciája: A generált relációs sémában ellenőriztük, hogy nincsenek-e “árva” rekordok (pl. olyan szerződés, amelyhez nem tartozik létező ügynök ID).
- Értéktartomány-vizsgálatok (Boundary Value Analysis): Ellenőriztük, hogy a generált adatok nem csúsznak-e ki az értelmezési tartományból (pl. nincs-e negatív jutalék, 100%-nál nagyobb jutalékkulcs, vagy jövőbeli szerződéskötési dátum).
III. Üzleti logika és időbeliség validálása (Döntési táblák alapján)
Bár az AI statisztikailag generál, az üzleti logikát is be kellett tartania. A tesztelők döntési táblákat és logikai szabályokat írtak a kimenetek szűrésére:
| Vizsgált Üzleti Esemény | Generált Adat Logikai Feltétele | Várható Teszt Eredmény |
| Kötés és storno sorrend | SIKER (Konzisztens életút) | |
| Kötés és storno sorrend | HIBA (AI logikai hiba) | |
| Kifizetési feltétel | Jutalék csak aktív ügynöknek generálható | SIKER |
| Kifizetési feltétel | Jutalék generálása inaktív ügynöknek | HIBA (AI üzleti szabály sértés) |
IV. Adatvédelmi penetrációs teszt (Privacy & Re-identification)
A GDPR megfelelőség matematikai bizonyítása érdekében a biztonsági és QA csapat szándékos támadásokat indított a generált adatok ellen:
- Távolság-alapú adatszivárgási teszt (Distance to Closest Record – DCR): Megmértük a generált szintetikus rekordok távolságát a legközelebbi valós történelmi rekordokhoz képest. Ha a távolság túl kicsi (közel nulla), az azt jelenti, hogy az AI nem generált, hanem lemásolta az éles adatot (memorizáció). Az ilyen modelleket a tesztelők elutasították.
- Linkage Attack szimuláció: Kísérletet tettünk a szintetikus adatokban szereplő profilok összekapcsolására publikus/külső adatokkal. A cél a k-anonymity és l-diversity metrikák igazolása volt.
Technikai megvalósítás és eszközök
A tesztelési keretrendszert modern technológiai stackkel valósítottuk meg:
- Synthetic Data Vault (SDV) Evaluation: Az SDV saját kiértékelő moduljának használata a szintetikus adatok minősítésére. (Forrás: SDV Metrics & Evaluation Docs)
- Pandas és SciPy (Python): A statisztikai tesztek (KS-test, Chi-square) automatizálására és a korrelációs mátrixok vizualizálására.
- SQL / dbt (data build tool): Az adatbázis szintű relációs és strukturális tesztek automatikus futtatására a szintetikus adatok Postgres/Snowflake-be való betöltése után.
- Jenkins pipeline: Az AI-modell minden egyes újra-tanítása után automatikusan lefutott a teljes QA tesztcsomag. Ha a modell pontossági (fidelity) vagy biztonsági pontszáma a határértékek alá esett, a pipeline elbukott, megakadályozva a hibás adatgenerátor élesítését.
Eredmények és megtalált hibák
Az AI-alapú szintetikus adatgenerátor tesztelése során a QA csapat 14 komoly hiányosságot és hibát tárt fel magában az AI modell működésében a bevezetés előtt:
- Szülő-gyermek elárvulás (4 eset): Az AI kezdetben nem tudta tökéletesen leképezni az ügynök-szerződés hierarchiát, így olyan szerződésekhez is generált jutalékokat, amelyeknél az ügynök az adott időszakban még nem is létezett a rendszerben.
- Logikai storno anomáliák (6 eset): Az időbeli összefüggések gyenge tanulása miatt az AI az esetek 3%-ában a szerződéskötés dátuma elé generálta a stornó eseményt.
- Negatív jutalékértékek (2 eset): A CTGAN modell a szélsőértékek becslésekor elvétve negatív kifizetési összegeket generált, ami a jutalékrendszerben értelmezhetetlen.
- Adatszivárgási kockázat (2 eset): A DCR vizsgálat kimutatta, hogy a modell a ritka, prémium ügyfelek adatait (ahol nagyon kevés minta állt rendelkezésre a tanuláshoz) hajlamos volt szinte egy az egyben lemásolni.
A hibák javítása: A QA visszajelzései alapján az AI fejlesztő csapat finomhangolta a CTGAN hiperparamétereit, bevezette a TVAE modellt a stabilabb struktúrákhoz, és a generátor kimenetére egy szabályalapú utófeldolgozó (post-processing) szűrőréteget épített, amely a logikai anomáliákat automatikusan korrigálta.
Üzleti haszon és a jutalékrendszer sikeres tesztelése
Miután a QA csapat igazolta, hogy az AI adatgenerátor stabilan, helyesen és biztonságosan működik, a szintetikus adathalmazt élesítették a jutalékrendszer tesztkörnyezetében.
Ennek közvetlen eredményei:
- 24 kritikus bug azonosítása: A jutalékelszámolási rendszer tesztelése során a szintetikus adatokkal olyan komplex, ritka életutakat és ügynöki láncolatokat szimuláltunk, amelyekkel 24 olyan kritikus számítási és kerekítési hibát találtunk meg, amelyek a korábbi manuális tesztadatokkal rejtve maradtak volna.
- 100% GDPR megfelelőség: A belső adatvédelmi audit tanúsította, hogy a tesztadatok teljesen szintetikusak, így a tesztelés során a személyes adatok sérülésének kockázata nullára csökkent.
- Drámai időmegtakarítás: A tesztadatok előállítása hetek helyett másodpercek alatt történik, a regressziós tesztadatbázis felépítése teljesen automatizálttá vált a CI/CD pipeline-ban.
Összegzés
Ez a projekt rávilágított arra, hogy a mesterséges intelligencia nemcsak a fejlesztést, hanem a szoftvertesztelést is forradalmasítja. Ugyanakkor az AI bevezetése új típusú minőségbiztosítási megközelítést igényel. A nem-determinisztikus működés és az adatbiztonsági kockázatok miatt magát az AI rendszert is szigorú, statisztikai és logikai tesztelés alá kell vetni, mielőtt megbízunk a kimeneteiben. A strukturált QA stratégia volt a kulcsa annak, hogy a biztosítótársaság pénzügyi szívét jelentő jutalékrendszert teljes biztonsággal és maximális lefedettséggel tudjuk tesztelni.


